Showing
- doc/source/_static/img/mr-resolve.png 0 additions, 0 deletionsdoc/source/_static/img/mr-resolve.png
- doc/source/_static/img/mr-respond.png 0 additions, 0 deletionsdoc/source/_static/img/mr-respond.png
- doc/source/_templates/layout.html 2 additions, 0 deletionsdoc/source/_templates/layout.html
- doc/source/api.rst 11 additions, 0 deletionsdoc/source/api.rst
- doc/source/cbc_analysis.rst 743 additions, 0 deletionsdoc/source/cbc_analysis.rst
- doc/source/conf.py 35 additions, 21 deletionsdoc/source/conf.py
- doc/source/container_environment.md 97 additions, 0 deletionsdoc/source/container_environment.md
- doc/source/contributing.md 100 additions, 0 deletionsdoc/source/contributing.md
- doc/source/contributing_docs.md 17 additions, 0 deletionsdoc/source/contributing_docs.md
- doc/source/executables.rst 10 additions, 0 deletionsdoc/source/executables.rst
- doc/source/extrinsic_parameters_generation.rst 175 additions, 0 deletionsdoc/source/extrinsic_parameters_generation.rst
- doc/source/feature_extraction.rst 99 additions, 21 deletionsdoc/source/feature_extraction.rst
- doc/source/getting-started.rst 0 additions, 33 deletionsdoc/source/getting-started.rst
- doc/source/gstlal-burst/code.rst 0 additions, 8 deletionsdoc/source/gstlal-burst/code.rst
- doc/source/gstlal-burst/gstlal-burst.rst 0 additions, 19 deletionsdoc/source/gstlal-burst/gstlal-burst.rst
- doc/source/gstlal-burst/tutorials/running_offline_jobs.rst 0 additions, 77 deletionsdoc/source/gstlal-burst/tutorials/running_offline_jobs.rst
- doc/source/gstlal-burst/tutorials/running_online_jobs.rst 0 additions, 86 deletionsdoc/source/gstlal-burst/tutorials/running_online_jobs.rst
- doc/source/gstlal-burst/tutorials/tutorials.rst 0 additions, 9 deletionsdoc/source/gstlal-burst/tutorials/tutorials.rst
- doc/source/gstlal-calibration/code.rst 0 additions, 8 deletionsdoc/source/gstlal-calibration/code.rst
- doc/source/gstlal-calibration/gstlal-calibration.rst 0 additions, 7 deletionsdoc/source/gstlal-calibration/gstlal-calibration.rst
Some changes are not shown.
For a faster browsing experience, only 20 of 213+ files are shown.
doc/source/_static/img/mr-resolve.png
0 → 100644
{kind=link}
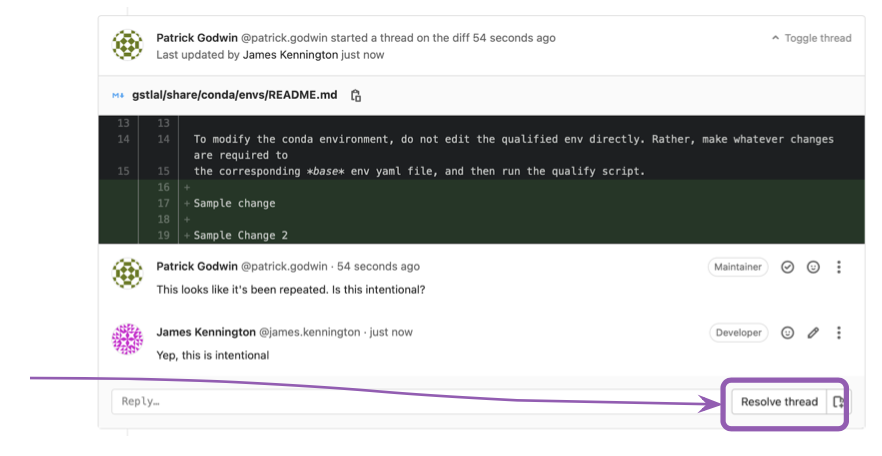
109 KiB
doc/source/_static/img/mr-respond.png
0 → 100644
{kind=link}
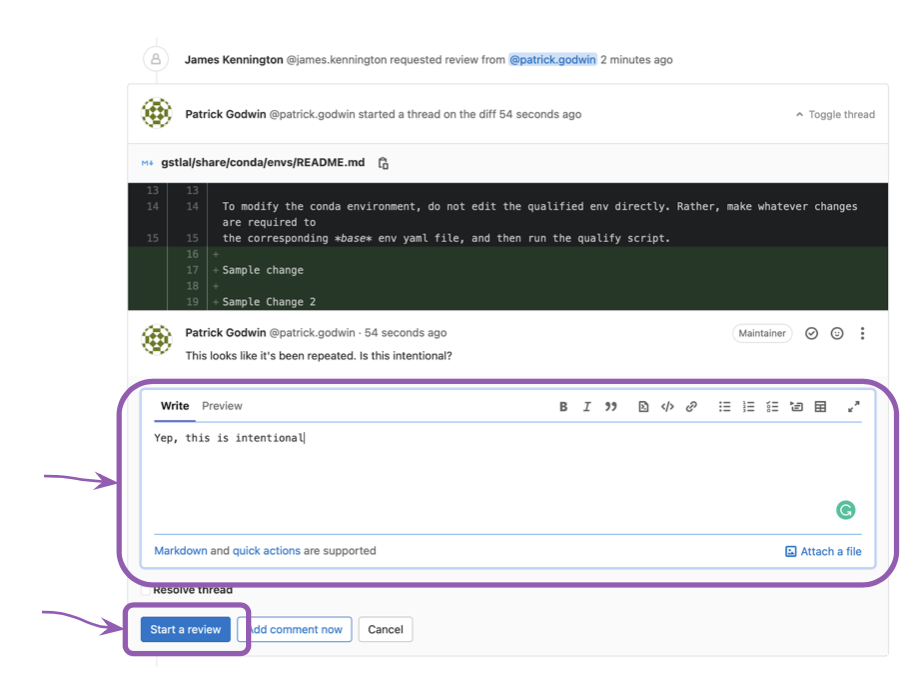
132 KiB
doc/source/_templates/layout.html
0 → 100644
doc/source/api.rst
0 → 100644
doc/source/cbc_analysis.rst
0 → 100644
doc/source/container_environment.md
0 → 100644
doc/source/contributing.md
0 → 100644
doc/source/contributing_docs.md
0 → 100644
doc/source/executables.rst
0 → 100644
doc/source/getting-started.rst
deleted
100644 → 0
doc/source/gstlal-burst/code.rst
deleted
100644 → 0