-
- Downloads
There was a problem fetching the pipeline summary.
Add documentation for basic of PE
parent
eaf8d4d7
No related branches found
No related tags found
Pipeline #
Showing
- docs/basics-of-parameter-estimation.txt 113 additions, 0 deletionsdocs/basics-of-parameter-estimation.txt
- docs/images/linear-regression_corner.png 0 additions, 0 deletionsdocs/images/linear-regression_corner.png
- docs/images/linear-regression_data.png 0 additions, 0 deletionsdocs/images/linear-regression_data.png
- docs/index.txt 1 addition, 0 deletionsdocs/index.txt
- examples/other_examples/linear_regression.py 1 addition, 1 deletionexamples/other_examples/linear_regression.py
docs/basics-of-parameter-estimation.txt
0 → 100644
docs/images/linear-regression_corner.png
0 → 100644
{kind=link}
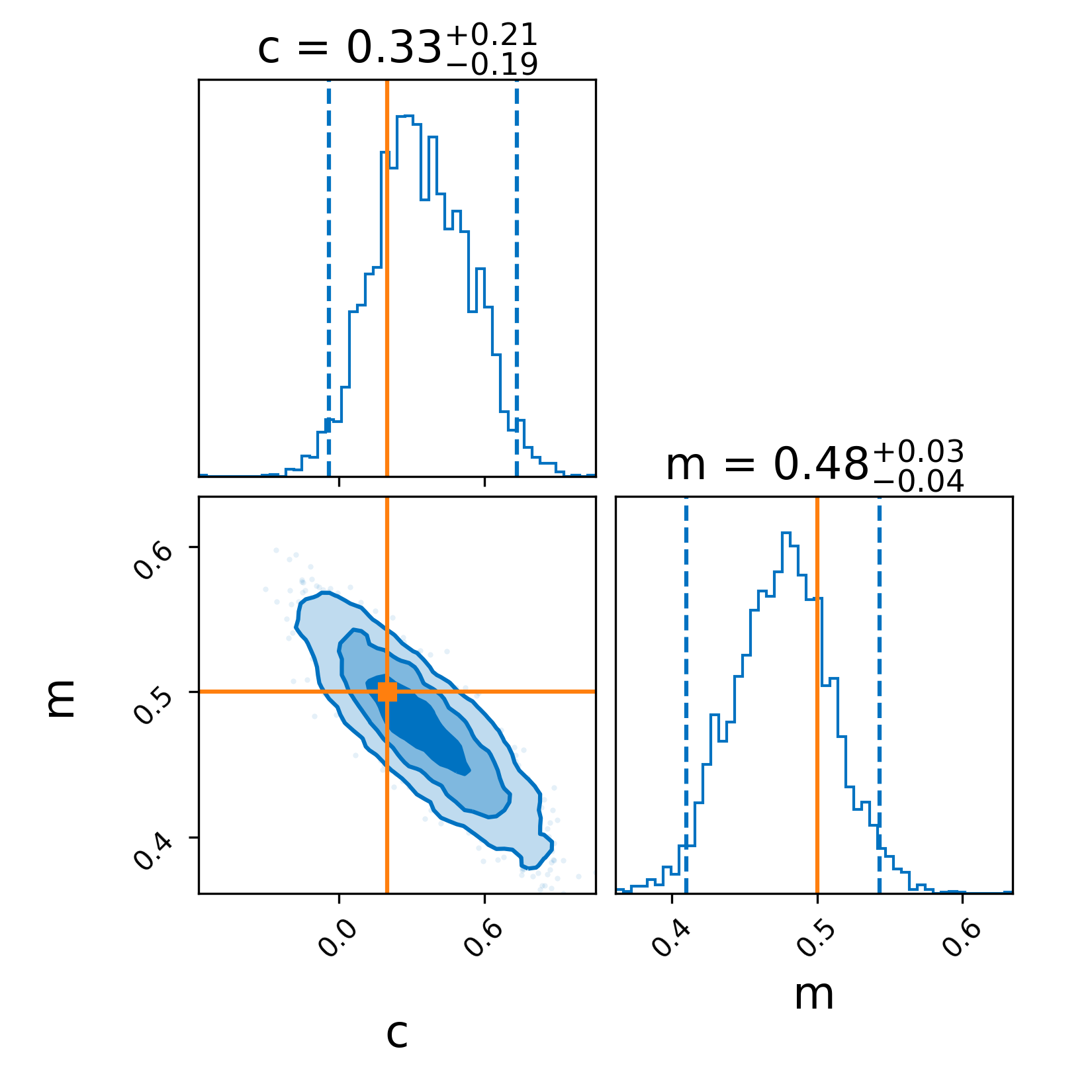
110 KiB
docs/images/linear-regression_data.png
0 → 100644
{kind=link}

22.2 KiB